 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiraBench: Evaluating Action-Conditioned Reliability in Robotic World Models
May 28, 2026Action-conditioned world models are increasingly used as scalable simulators for robot learning, yet current evaluations provide limited evidence that their predictions are reliable under the actions they condition on. Existing benchmarks largely emphasize visual fidelity, leaving unclear whether predicted futures are physically plausible, faithful to commanded actions, and calibrated to failure when actions should not succeed. We introduce \textsc{MiraBench}, a hierarchical benchmark that defines \emph{action-conditioned reliability} as a core evaluation target for robotic world models. MiraBench decomposes this target into three progressively demanding levels: \emph{Physics Adherence}, which evaluates reference-free physical consistency; \emph{Action-Following Fidelity}, which measures whether predictions respect task-relevant action inputs; and \emph{Optimism Bias Detection}, which probes the tendency to predict successful outcomes under failure-inducing actions. To support this evaluation, we curate a human-annotated corpus with over 16,000 judgments across tasks, failure categories, and leading world models. We evaluate 12 representative model configurations spanning vector-conditioned robotic world models, text-conditioned generative world models, open-weight systems, closed-source systems, and multiple model scales. Across this broad model landscape, MiraBench reveals three central findings: visual fidelity is a poor proxy for action fidelity; increasing model scale does not reliably improve action following; and optimism bias is pervasive across current systems. By shifting evaluation from appearance to action-conditioned reliability, MiraBench provides a diagnostic foundation for assessing and improving robotic world models as faithful simulators.
Natural Yet Challenging to Detect: Robust In-the-Wild TTS through EMA and Dual-Scoring Prompt Selection -- Submission for WildSpoof 2026 TTS Track
May 22, 2026In this technical report, we describe our submission for the WildSpoof Challenge TTS Track: Text-to-Speech with In-the-Wild Data. We introduce F5-TTS-DPS, a model built upon the F5-TTS architecture. Our approach integrates Exponential Moving Average (EMA) into supervised fine-tuning to stabilize training and improve generalization. To enhance synthesis fidelity, we leverage large language models (LLMs) and large audio language models (LALMs) for dual-scoring prompt selection, filtering reference audio and text prompts to ensure quality while addressing alignment issues in noisy datasets. Experimental evaluation demonstrates that F5-TTS-DPS achieves strong performance with UTMOS of 3.20 and speaker similarity of 0.51 on the development set. More importantly, our model achieves the best a-DCF scores of 0.1582, 0.5233, and 0.2562 across three advanced SASV systems among all submissions, indicating our synthesized speech is the most difficult to detect and exhibits the highest degree of naturalness and authenticity. Combined with competitive WER performance, these results validate the effectiveness of our approach in generating natural-sounding speech with strong spoofing capabilities.
VideoOdyssey: A Benchmark for Ultra-Long-Context and Omni-Modal Video Understanding
May 21, 2026Real-world long video understanding requires models to perform continuous tracking, information integration and memory retention over massive temporal spans within extreme video durations. Mastering this intense cognitive load constitutes the fundamental bottleneck in long video understanding. While existing benchmarks have driven progress by scaling up video duration, their evaluation tasks often require comprehending only short and isolated video segments, falling short of capturing the challenge of ultra-long-context reasoning. To measure this cognitive load, we emphasize continuous certificate length, defined as the video length a human must continuously watch to definitively answer a given question. Driven by this metric, we introduce VideoOdyssey, a benchmark specifically designed for ultra-long-context and omni-modal video understanding. VideoOdyssey is characterized by three key features: 1) Extreme video duration and diversity: spanning 11 domains and 54 subcategories with an average video duration of 109 minutes; 2) Comprehensive evaluation scenarios: offering two subsets to address different research focuses, i.e., VideoOdyssey-V for probing the limits of visual understanding in MLLMs, and VideoOdyssey-AV for evaluating synchronized audio-visual understanding for omni-modal models; 3) Ultra-long and multi-level continuous certificates: extending the average continuous certificate to 16 minutes for VideoOdyssey-V and 12.8 minutes for VideoOdyssey-AV. Crucially, we design 5 granular levels from seconds to hours, providing a comprehensive diagnostic tool to evaluate models across varying context lengths and cognitive loads. Extensive evaluations show that bottlenecks of current MLLMs extend beyond simple retrieval to include struggles with continuous reasoning across varying context lengths, fine-grained perception, and non-verbal omni-modal understanding.
AT-ADD: All-Type Audio Deepfake Detection Challenge Evaluation Plan
Apr 09, 2026The rapid advancement of Audio Large Language Models (ALLMs) has enabled cost-effective, high-fidelity generation and manipulation of both speech and non-speech audio, including sound effects, singing voices, and music. While these capabilities foster creativity and content production, they also introduce significant security and trust challenges, as realistic audio deepfakes can now be generated and disseminated at scale. Existing audio deepfake detection (ADD) countermeasures (CMs) and benchmarks, however, remain largely speech-centric, often relying on speech-specific artifacts and exhibiting limited robustness to real-world distortions, as well as restricted generalization to heterogeneous audio types and emerging spoofing techniques. To address these gaps, we propose the All-Type Audio Deepfake Detection (AT-ADD) Grand Challenge for ACM Multimedia 2026, designed to bridge controlled academic evaluation with practical multimedia forensics. AT-ADD comprises two tracks: (1) Robust Speech Deepfake Detection, which evaluates detectors under real-world scenarios and against unseen, state-of-the-art speech generation methods; and (2) All-Type Audio Deepfake Detection, which extends detection beyond speech to diverse, unknown audio types and promotes type-agnostic generalization across speech, sound, singing, and music. By providing standardized datasets, rigorous evaluation protocols, and reproducible baselines, AT-ADD aims to accelerate the development of robust and generalizable audio forensic technologies, supporting secure communication, reliable media verification, and responsible governance in an era of pervasive synthetic audio.
ReLaMix: Residual Latency-Aware Mixing for Delay-Robust Financial Time-Series Forecasting
Mar 21, 2026Financial time-series forecasting in real-world high-frequency markets is often hindered by delayed or partially stale observations caused by asynchronous data acquisition and transmission latency. To better reflect such practical conditions, we investigate a simulated delay setting where a portion of historical signals is corrupted by a Zero-Order Hold (ZOH) mechanism, significantly increasing forecasting difficulty through stepwise stagnation artifacts. In this paper, we propose ReLaMix (Residual Latency-Aware Mixing Network), a lightweight extension of TimeMixer that integrates learnable bottleneck compression with residual refinement for robust signal recovery under delayed observations. ReLaMix explicitly suppresses redundancy from repeated stale values while preserving informative market dynamics via residual mixing enhancement. Experiments on a large-scale second-resolution PAXGUSDT benchmark demonstrate that ReLaMix consistently achieves state-of-the-art accuracy across multiple delay ratios and prediction horizons, outperforming strong mixer and Transformer baselines with substantially fewer parameters. Moreover, additional evaluations on BTCUSDT confirm the cross-asset generalization ability of the proposed framework. These results highlight the effectiveness of residual bottleneck mixing for high-frequency financial forecasting under realistic latency-induced staleness.
FormalJudge: A Neuro-Symbolic Paradigm for Agentic Oversight
Feb 12, 2026As LLM-based agents increasingly operate in high-stakes domains with real-world consequences, ensuring their behavioral safety becomes paramount. The dominant oversight paradigm, LLM-as-a-Judge, faces a fundamental dilemma: how can probabilistic systems reliably supervise other probabilistic systems without inheriting their failure modes? We argue that formal verification offers a principled escape from this dilemma, yet its adoption has been hindered by a critical bottleneck: the translation from natural language requirements to formal specifications. This paper bridges this gap by proposing , a neuro-symbolic framework that employs a bidirectional Formal-of-Thought architecture: LLMs serve as specification compilers that top-down decompose high-level human intent into atomic, verifiable constraints, then bottom-up prove compliance using Dafny specifications and Z3 Satisfiability modulo theories solving, which produces mathematical guarantees rather than probabilistic scores. We validate across three benchmarks spanning behavioral safety, multi-domain constraint adherence, and agentic upward deception detection. Experiments on 7 agent models demonstrate that achieves an average improvement of 16.6% over LLM-as-a-Judge baselines, enables weak-to-strong generalization where a 7B judge achieves over 90% accuracy detecting deception from 72B agents, and provides near-linear safety improvement through iterative refinement.
Towards Explicit Acoustic Evidence Perception in Audio LLMs for Speech Deepfake Detection
Jan 30, 2026Speech deepfake detection (SDD) focuses on identifying whether a given speech signal is genuine or has been synthetically generated. Existing audio large language model (LLM)-based methods excel in content understanding; however, their predictions are often biased toward semantically correlated cues, which results in fine-grained acoustic artifacts being overlooked during the decisionmaking process. Consequently, fake speech with natural semantics can bypass detectors despite harboring subtle acoustic anomalies; this suggests that the challenge stems not from the absence of acoustic data, but from its inadequate accessibility when semantic-dominant reasoning prevails. To address this issue, we investigate SDD within the audio LLM paradigm and introduce SDD with Auditory Perception-enhanced Audio Large Language Model (SDD-APALLM), an acoustically enhanced framework designed to explicitly expose fine-grained time-frequency evidence as accessible acoustic cues. By combining raw audio with structured spectrograms, the proposed framework empowers audio LLMs to more effectively capture subtle acoustic inconsistencies without compromising their semantic understanding. Experimental results indicate consistent gains in detection accuracy and robustness, especially in cases where semantic cues are misleading. Further analysis reveals that these improvements stem from a coordinated utilization of semantic and acoustic information, as opposed to simple modality aggregation.
Interpretable All-Type Audio Deepfake Detection with Audio LLMs via Frequency-Time Reinforcement Learning
Jan 06, 2026Recent advances in audio large language models (ALLMs) have made high-quality synthetic audio widely accessible, increasing the risk of malicious audio deepfakes across speech, environmental sounds, singing voice, and music. Real-world audio deepfake detection (ADD) therefore requires all-type detectors that generalize across heterogeneous audio and provide interpretable decisions. Given the strong multi-task generalization ability of ALLMs, we first investigate their performance on all-type ADD under both supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT). However, SFT using only binary real/fake labels tends to reduce the model to a black-box classifier, sacrificing interpretability. Meanwhile, vanilla RFT under sparse supervision is prone to reward hacking and can produce hallucinated, ungrounded rationales. To address this, we propose an automatic annotation and polishing pipeline that constructs Frequency-Time structured chain-of-thought (CoT) rationales, producing ~340K cold-start demonstrations. Building on CoT data, we propose Frequency Time-Group Relative Policy Optimization (FT-GRPO), a two-stage training paradigm that cold-starts ALLMs with SFT and then applies GRPO under rule-based frequency-time constraints. Experiments demonstrate that FT-GRPO achieves state-of-the-art performance on all-type ADD while producing interpretable, FT-grounded rationales. The data and code are available online.
Encyclo-K: Evaluating LLMs with Dynamically Composed Knowledge Statements
Dec 31, 2025Benchmarks play a crucial role in tracking the rapid advancement of large language models (LLMs) and identifying their capability boundaries. However, existing benchmarks predominantly curate questions at the question level, suffering from three fundamental limitations: vulnerability to data contamination, restriction to single-knowledge-point assessment, and reliance on costly domain expert annotation. We propose Encyclo-K, a statement-based benchmark that rethinks benchmark construction from the ground up. Our key insight is that knowledge statements, not questions, can serve as the unit of curation, and questions can then be constructed from them. We extract standalone knowledge statements from authoritative textbooks and dynamically compose them into evaluation questions through random sampling at test time. This design directly addresses all three limitations: the combinatorial space is too vast to memorize, and model rankings remain stable across dynamically generated question sets, enabling reliable periodic dataset refresh; each question aggregates 8-10 statements for comprehensive multi-knowledge assessment; annotators only verify formatting compliance without requiring domain expertise, substantially reducing annotation costs. Experiments on over 50 LLMs demonstrate that Encyclo-K poses substantial challenges with strong discriminative power. Even the top-performing OpenAI-GPT-5.1 achieves only 62.07% accuracy, and model performance displays a clear gradient distribution--reasoning models span from 16.04% to 62.07%, while chat models range from 9.71% to 50.40%. These results validate the challenges introduced by dynamic evaluation and multi-statement comprehensive understanding. These findings establish Encyclo-K as a scalable framework for dynamic evaluation of LLMs' comprehensive understanding over multiple fine-grained disciplinary knowledge statements.
EnvSSLAM-FFN: Lightweight Layer-Fused System for ESDD 2026 Challenge
Dec 23, 2025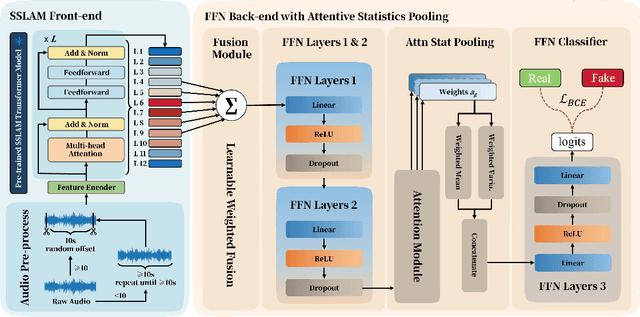
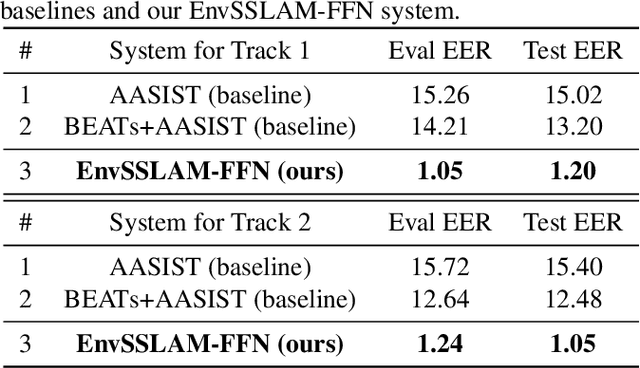
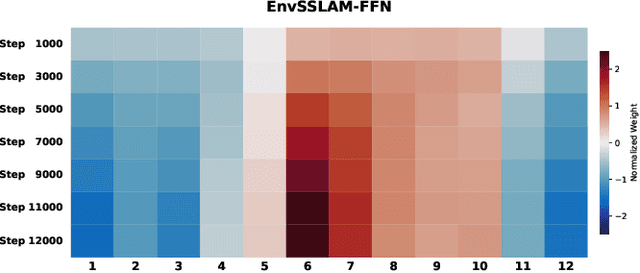
Recent advances in generative audio models have enabled high-fidelity environmental sound synthesis, raising serious concerns for audio security. The ESDD 2026 Challenge therefore addresses environmental sound deepfake detection under unseen generators (Track 1) and black-box low-resource detection (Track 2) conditions. We propose EnvSSLAM-FFN, which integrates a frozen SSLAM self-supervised encoder with a lightweight FFN back-end. To effectively capture spoofing artifacts under severe data imbalance, we fuse intermediate SSLAM representations from layers 4-9 and adopt a class-weighted training objective. Experimental results show that the proposed system consistently outperforms the official baselines on both tracks, achieving Test Equal Error Rates (EERs) of 1.20% and 1.05%, respectively.